
La inteligencia artificial y el aprendizaje profundo están constantemente en las noticias en estos días, ya sea que ChatGPT genere malos consejos, autos sin conductor, artistas acusados de usar IA, consejos médicos de IA, etc. La mayoría de estas herramientas se basan en servidores complejos con mucho hardware para el entrenamiento, pero el uso de la red entrenada a través de la inferencia se puede hacer en su PC, usando su tarjeta gráfica. Pero, ¿qué tan rápido las GPU de consumo hacen inferencias de IA?
Comparamos Stable Diffusion, un popular creador de imágenes de IA, en las últimas GPU de Nvidia, AMD e incluso Intel para ver cómo se comparan. Si por casualidad ha intentado ejecutar Stable Diffusion en su propia PC, es posible que tenga una idea de cuán complejo, ¡o cuán simple! - esto puede ser. El breve resumen es que las GPU de Nvidia gobiernan, con la mayoría del software creado con CUDA y otras herramientas de Nvidia. Pero eso no significa que no pueda ejecutar Stable Diffusion en otras GPU.
Terminamos usando tres proyectos Stable Diffusion diferentes para nuestras pruebas, principalmente porque ningún paquete funcionó en todas las GPU. Para Nvidia, optamos por la versión webui de Automatic 1111 (se abre en una nueva pestaña). Las GPU AMD se han probado con la versión Shark de Nod.ai (se abre en una nueva pestaña)mientras que para las GPU Intel Arc usamos Stable Diffusion OpenVINO (se abre en una nueva pestaña). Las renuncias están en orden. No codificamos ninguna de estas herramientas, pero buscamos cosas que fueran fáciles de ejecutar (en Windows) que también parecieran razonablemente optimizadas.
Estamos relativamente seguros de que las pruebas de la serie 30 de Nvidia logran extraer un rendimiento casi óptimo, especialmente con xformers habilitados, lo que ofrece un aumento de rendimiento adicional de ~20 %. Mientras tanto, los resultados de la serie RTX 40 están un poco por debajo de las expectativas, posiblemente debido a la falta de optimizaciones para la nueva arquitectura Ada Lovelace.
Los resultados de AMD también están un poco mezclados, pero son lo contrario de la situación de Nvidia: las GPU RDNA 3 funcionan bastante bien, mientras que las GPU RDNA 2 se ven bastante mediocres. Por último, en las GPU de Intel, aunque el rendimiento final parece alinearse muy bien con las opciones de AMD, en la práctica el tiempo de renderizado es considerablemente más largo; probablemente hay muchas cosas adicionales en segundo plano que lo ralentizan.
También usamos los modelos Stable Diffusion 1.4, en lugar de los nuevos SD 2.0 o 2.1, principalmente porque ejecutar SD2.1 en hardware que no es de Nvidia habría requerido mucho más trabajo (es decir, aprender a escribir código para habilitar el soporte). Sin embargo, si tiene un conocimiento profundo de Stable Diffusion y le gustaría recomendar diferentes proyectos de código abierto que puedan funcionar mejor que los que hemos usado, háganoslo saber en los comentarios (o simplemente envíe un correo electrónico a Jarred (se abre en una nueva pestaña)).
Fotografía 1 de 11

Nuestra configuración de prueba es la misma para todas las GPU, aunque no hay opciones para una opción de aviso negativo en la versión de Intel (al menos no que podamos encontrar). La galería de arriba se generó con la versión de Nvidia, con salidas de mayor resolución (que requieren mucho, un montón más tiempo para completar). Estas son las mismas indicaciones, pero apuntan a 2048x1152 en lugar de 512x512 que usamos para nuestros puntos de referencia. Aquí están los parámetros relevantes:
Indicación positiva:
ciudad steampunk postapocalíptica, exploración, cinematográfica, realista, hiperdetallada, máximo detalle fotorrealista, luz volumétrica, (((foco))), gran angular, (((brillantemente iluminada))), (((vegetación))), relámpagos, vides, destrucción, devastación, guerra, ruinas
Indicación negativa:
(((borroso))), ((niebla)), (((oscuro))), ((monocromo)), sol, (((profundidad de campo)))
No:
100
Guía clasificadora gratuita:
15.0
Algoritmo de muestreo:
Algunas variantes de Euler (Ancestral, Discreto)
El algoritmo de muestreo no parece afectar significativamente el rendimiento, aunque puede afectar la salida. Automatic 1111 ofrece la mayoría de las opciones, mientras que la versión Intel OpenVINO no le da otra opción.
Estos son los resultados de nuestras pruebas de las GPU de la serie AMD RX 7000/6000, Nvidia RTX 40/30 y la serie Intel Arc A. Tenga en cuenta que cada GPU Nvidia tiene dos resultados, uno que usa el modelo de cómputo predeterminado (más lento y negro) y un segundo usando la biblioteca "xformers" más rápida de Facebook (se abre en una nueva pestaña) (más rápido y en verde).
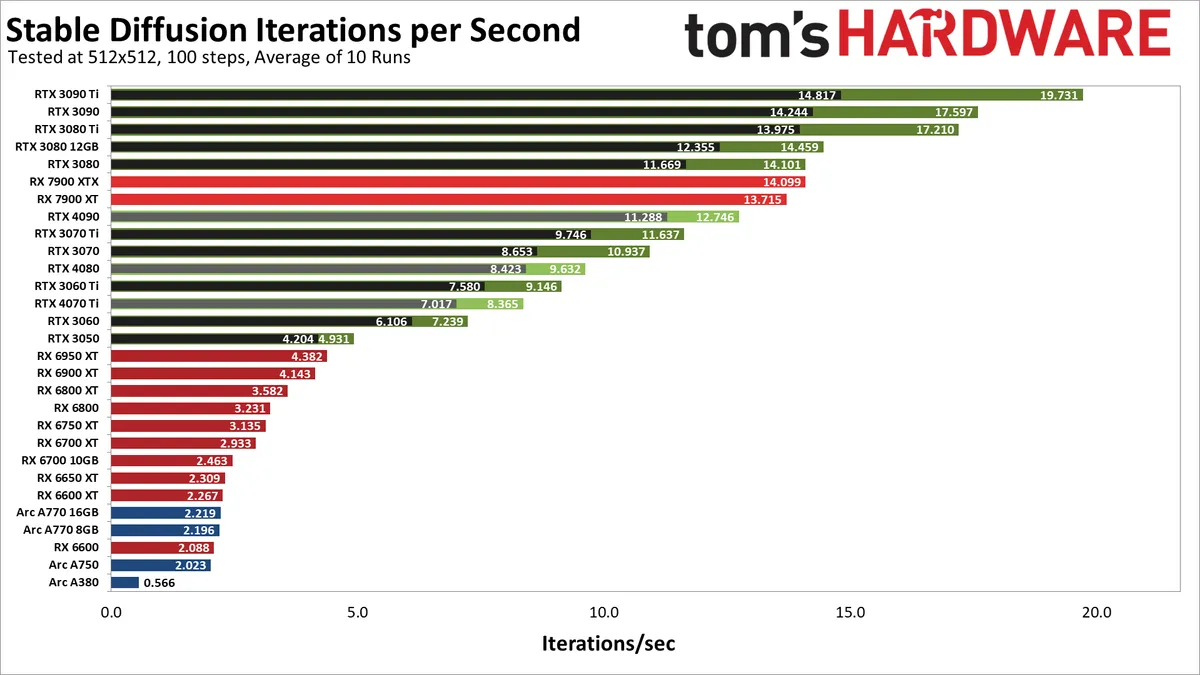
Como era de esperar, las GPU de Nvidia ofrecen un rendimiento superior, a veces por grandes márgenes, a las de AMD o Intel. Sin embargo, hay claramente anomalías. La GPU más rápida en nuestras pruebas iniciales fue la RTX 3090 Ti, que logró casi 20 iteraciones por segundo, o alrededor de cinco segundos por cuadro usando la configuración configurada. Las cosas se desmoronan a partir de ahí, pero incluso el RTX 3080 esencialmente vincula al nuevo RX 7900 XTX de AMD, y el RTX 3050 supera al RX 6950 XT. Pero hablemos de las rarezas.
Primero, esperábamos que la RTX 4090 aplastara a la competencia, y eso claramente no sucedió. De hecho, es más lento que el 7900 XT de AMD y también más lento que el RTX 3080. Del mismo modo, el RTX 4080 se encuentra entre el 3070 y el 3060 Ti, mientras que el RTX 4070 Ti se encuentra entre el 3060 y el 3060 Ti.
Las optimizaciones adecuadas podrían duplicar fácilmente el rendimiento de las tarjetas de la serie RTX 40. Del mismo modo, dada la gran brecha de rendimiento entre la RX 7900 XT y la RX 6950 XT, sus optimizaciones también podrían duplicar el rendimiento de las GPU RDNA 2 hemos visto en nuestra jerarquía de referencia de GPU, pero definitivamente hay algo extraño en estos primeros resultados.
Las GPU Arc de Intel actualmente ofrecen resultados muy decepcionantes, especialmente porque admiten operaciones XMX (matrices) que deberían proporcionar hasta 4 veces el rendimiento de los cálculos regulares de FP32. Sospechamos que el proyecto actual Stable Diffusion OpenVINO que hemos estado usando también deja mucho margen de mejora. Por cierto, si desea intentar ejecutar SD en una GPU Arc, tenga en cuenta que debe editar el archivo 'stable_diffusion_engine.py' y cambiar "CPU" a "GPU"; de lo contrario, no utilizará las tarjetas gráficas para cálculos y tomas. mucho mas largo.
Volver a los resultados. Usando las compilaciones especificadas, las tarjetas de la serie RTX 30 de Nvidia funcionan muy bien, las tarjetas de la serie RX 7000 de AMD funcionan muy bien, la serie RTX 40 tiene un rendimiento inferior, la serie RX 6000 realmente tiene un rendimiento inferior y las GPU Arc generalmente parecen mediocres. Las cosas podrían cambiar drásticamente con el software actualizado, y dada la popularidad de la IA, creemos que es solo cuestión de tiempo antes de que veamos una mejor configuración (o encontremos el proyecto correcto que ya está ajustado para un mejor rendimiento).
Nuevamente, no está claro exactamente qué tan optimizados están estos proyectos, pero podría valer la pena observar el rendimiento teórico máximo (TFLOPS) de diferentes GPU. El siguiente gráfico muestra el rendimiento teórico del FP16 para cada GPU, utilizando núcleos de matriz/tensor cuando corresponda.

Estos núcleos Tensor en Nvidia claramente tienen un gran impacto, al menos en teoría, aunque nuestras pruebas de transmisión estable obviamente no coinciden exactamente con esos números. Por ejemplo, sobre el papel, la RTX 4090 (usando FP16) es hasta un 106 % más rápida que la RTX 3090 Ti, mientras que en nuestras pruebas fue un 35 % más lenta. También tenga en cuenta que asumimos que el proyecto Stable Diffusion que usamos (Automatic 1111) ni siquiera intenta aprovechar las nuevas instrucciones FP8 en las GPU Ada Lovelace, lo que podría duplicar el rendimiento nuevamente en la serie RTX 40.
Mientras tanto, mira las GPU Arc. Sus núcleos de matriz deberían ofrecer un rendimiento similar al de la RTX 3060 Ti y la RX 7900 XTX, más o menos, con la A380 alrededor de la RX 6800. En la práctica, las GPU Arc están muy por debajo de esas marcas. Las GPU A770 más rápidas se ubican entre la RX 6600 y la RX 6600 XT, la A750 está justo detrás de la RX 6600 y la A380 tiene aproximadamente una cuarta parte de la velocidad de la A750. Por lo tanto, representan aproximadamente una cuarta parte del rendimiento esperado, lo que tendría sentido si no se utilizan los núcleos XMX.
Sin embargo, las proporciones en Arc parecen correctas. El rendimiento informático teórico en el A380 es aproximadamente una cuarta parte del A750. Lo más probable es que usen sombreadores para los cálculos, en modo FP32 de precisión total, y pierdan algunas optimizaciones adicionales.
La otra cosa a tener en cuenta es que el cálculo teórico en el RX 7900 XTX/XT de AMD es mucho mejor que el de la serie RX 6000, y el ancho de banda de la memoria no es un factor crítico: los modelos 3080 de 10 GB y 12 GB están relativamente cerca uno del otro. Entonces, tal vez los resultados de AMD anteriores no estén completamente descartados, ya que el 7900 XTX realiza casi el triple de cómputo sin procesar en comparación con el 6950 XT. Excepto que el 7900 XT funciona casi tan bien como el XTX, donde las matemáticas brutas deberían favorecer al XTX en alrededor de un 19 % en lugar del 3 % que medimos.
En última instancia, esto es más una instantánea en el tiempo del rendimiento de transmisión estable en las GPU AMD, Intel y Nvidia que una verdadera declaración de rendimiento. Con optimizaciones completas, el rendimiento debería parecerse más al gráfico TFLOPS teórico, y las nuevas tarjetas de la serie RTX 40 ciertamente no deberían quedarse atrás de las piezas de la serie RTX 30 existentes.

Lo que nos lleva a un gráfico final, donde realizamos algunas pruebas de mayor resolución. Todavía no hemos probado todas las nuevas GPU y hemos usado Linux en las tarjetas de la serie AMD RX 6000 que hemos probado. Pero parece que la resolución objetivo más compleja de 2048x1152 ha comenzado a aprovechar al menos el RTX 4090. Veremos cómo volver a este tema más en el próximo año.
Deja una respuesta